1 Introduction¶
It is clear that Registry database schema will continue to improve and evolve over time and there is a need for a well-defined migration process and tools to support that process.
This technical note describes a proposed design of the system to support schema evolution of the Registry database. The system is based on Alembic which is a tool developed to support schema migration for the database applications built with SQLAlchemy. This is the summary of work performed on DM-29593 ticket, many more details of the process are available on that ticket.
2 Schema Versions in Registry¶
Overall Registry database and schema is split into several domains, today there are six domains defined: - attributes - dimensions - collections - datasets - opaque - datastores
Each domain is controlled by a manager which is an instance of a Python class. Schema of the corresponding domain is determined by the manager class and also by its version number. All versions have a “semantic” numbering format (MAJOR.MINOR.PATCH) and compatibility rules.
For a particular domain there may be more than one class implementing manager
for that domain, specific class to use is determined by Butler configuration
when REgistry database is created. The version of the class is defined by the
class itself and is exposed via member method. When a Registry database is
created all manager classes and their corresponding versions are recorded as a
database metadata in a special table with the name butller_attributes.
Here is an example of the manager class names stored in that table:
name | value
--------------------------------------+-----------------------------------------------------------------------------------------------------
config:registry.managers.attributes | lsst.daf.butler.registry.attributes.DefaultButlerAttributeManager
config:registry.managers.collections | lsst.daf.butler.registry.collections.synthIntKey.SynthIntKeyCollectionManager
config:registry.managers.datasets | lsst.daf.butler.registry.datasets.byDimensions._manager.ByDimensionsDatasetRecordStorageManagerUUID
config:registry.managers.datastores | lsst.daf.butler.registry.bridge.monolithic.MonolithicDatastoreRegistryBridgeManager
config:registry.managers.dimensions | lsst.daf.butler.registry.dimensions.static.StaticDimensionRecordStorageManager
config:registry.managers.opaque | lsst.daf.butler.registry.opaque.ByNameOpaqueTableStorageManager
And this is an example of how version numbers are stored in the same table (some names are truncated to make it fit on a page):
name | value
-----------------------------------------------------------------------------------
version:lsst.daf.butler.registry.attributes.DefaultButlerAttributeManager | 1.0.0
version:<...>.bridge.monolithic.MonolithicDatastoreRegistryBridgeManager | 0.2.0
version:<...>.collections.synthIntKey.SynthIntKeyCollectionManager | 2.0.0
version:<...>.datasets.<...>.ByDimensionsDatasetRecordStorageManagerUUID | 1.0.0
version:<...>.dimensions.static.StaticDimensionRecordStorageManager | 6.0.0
version:lsst.daf.butler.registry.opaque.ByNameOpaqueTableStorageManager | 0.2.0
In addition to version numbers we also store a schema digest for each manager, this allows us to detect inadvertent schema changes. Digest is calculated from the definition of all tables controlled by a manager, digest value is stable for a particular back-end but can differ between back-ends.
Obviously schema definitions are not completely independent, e.g. column types used for foreign keys in one manager need to be the same as types of primary keys of referenced table, and the referenced table can belong to a different manager. Thus the schema definition is a function of version number not only of its own manager but also another manager. To simplify our model we ignore that extra dependency and assume that managers are independent, while at the same time understanding that change in a version of one manager can trigger changes in the tables controlled by other managers. Better way to put it may be that management boundaries are not at table level but at individual column level, but that can become complicated too.
3 Schema Changes and Migrations¶
Every new database created by Registry code uses the latest/current versions of all configured managers defined in the release. When new release is deployed with the existing database the code in the release could have newer version of one or few managers. These new version may be incompatible with the database schema, in that case database schema needs a schema upgrade to match schema version in a new release.
Usually for any incremental schema version change there is a corresponding schema upgrade process called a migration which is a single step bringing database schema from one well-defined state/version into a new state. In some cases release upgrade can result in several migration steps that need to be performed sequentially, e.g. 1.0.0 → 1.0.1 → 1.1.0.
Migrations can include any combination of DDL and DML statements that need to be executed on a database, few simple examples: - creating new table or dropping existing one - adding or dropping columns from a table - inserting/replacing values into columns based on values of existing columns
Some trivial migrations can be performed while users are still using the database, but more complex migrations usually require a scheduled downtime to avoid conflicts.
Schema versions and their corresponding migrations are typically ordered, migrations have to be applied in a specific order. In case of multiple unrelated sub-schemas their respective order may not matter, though in some cases there may be implied dependencies between versions of those sub-schemas.
Registry schema management is complicated by the fact that there may be more than one implementation of a particular manager type. In this situation schema migration may include two distinct types of changes:
- Regular incremental changes in version of a particular implementation class,
e.g. switching from version 1.0.0 of
DefaultButlerAttributeManagerclass to version 1.0.1 of the same class. - Switching to different implementation class of the same manager.
For latter case there is no implied ordering between the versions of different manager implementations. If for example we have two manager classes ManagerA and ManagerB, each with its own versions, then these migrations may be necessary to support:
- from ManagerA 1.0.0 to ManagerB 1.0.0
- from ManagerA 1.2.0 to ManagerB 1.0.1
- from ManagerB 1.0.1 to ManagerA 1.0.0
- from ManagerB 1.0.1 to ManagerA 2.0.0
Using git analogy regular migrations (for the same manager class) can be
represented as a linear history on a single revision branch. Latter switching
between managers can be thought of as a “checkout” of some state on a
different branch, with a complication that data in the database needs to be
“ported” to that new branch.
4 Migration Tools¶
Probably most commonly used tools for schema upgrades is just a collection of SQL scripts that are executed manually by DBAs. In more complicated cases when complex migrations are needed it may also involve dynamic applications which can generate new data or mange dynamic parts of schema. One common complication for such tools is management of multiple variants of migrations and controlling their execution. More advanced migration tools can derive current schema version used by a database from database contents and can automate application of all necessary migrations to bring database up to date.
One of such advanced tools is Alembic. It is designed to work optimally with SQLAlchemy which makes it attractive for our use case as our Registry’s SQL back-end build on top of SQLAlchemy. Alembic is used extensively by many open source software projects and there is significant experience available for support.
Summary of the main Alembic features:
- Alembic is built on ideas of revisions and migrations, revision is a named version of a database schema (or part of the schema), migration is a script which is ran by alembic to upgrade (or downgrade) schema from one revision to another.
- Revision names have a syntax of identifier (few characters are reserved and cannot be used in a revision name). Revision names generated by Alembic itself are 12-character hex strings, but client can provide alternative name.
- Migration scripts are regular Python scripts which contain some metadata, most important is its parent revision(s) and final revision. Migrations are identified by the revisions, normally there cannot be more than one migration script for a revision.
- Alembic has some support for branching and merging of revisions, somewhat
similar to
gitbranches (but not exactly). It also supports collection of completely independent revision branches (a.k.a. forest). - Alembic needs to store database current revision(s) in a special table in a
database (named
alembic_version), there is one record for each active revision branch. - Whole revision history is derived from the contents of migration scripts, the database does not store its history.
- Alembic has flexible configuration, allowing to separate migration scripts into multiple directories and including/excluding those directories.
- Alembic has CLI with large command set to manage and apply migrations, and Python API which allows execution of the same tasks from any Python script.
This extensive set of features should allow us to design the process that satisfies our requirements and build a tool that wraps those features into a set of command with specific knowledge of Registry design.
5 Versions and Revisions¶
Alembic history and database current state is expressed in terms of Alembic revisions. Registry identifies its schema state using manager class names and their version numbers. It would be nice to avoid unnecessary duplication and translation between two sets of identifiers that represent essentially the same state.
We already store Registry versions in butler_attributes table, one obvious
idea is to avoid using alembic_version table to keep alembic revisions and
derive those revisions from Registry versions instead. Unfortunately Alembic
doe not provide enough encapsulation for its alembic_version table to try
to replace it cleanly with some other mechanism so it is hard to avoid using
that table. Still, this idea may be attractive and it may be possible to send
a request to Alembic developers to add support for that feature, or make a
pull request adding that feature.
Alembic revisions names can be almost arbitrary strings with some limitations:
- they cannot contain
-,+or@characters - migration script name usually includes revision name so it should avoid using characters that are potentially problematic in file names (slashes, colons, semicolons, etc.)
We could use Registry version identifier in some encoded format to represent
Alembic revisions. One obvious way could be to combine manager class name and
its version, but unfortunately manager class names are unwieldy long which
makes it hard for humans to work with. An example could be name like
ByDimensionsDatasetRecordStorageManager_0.1.0, would be hard to parse,
especially if there are few revisions appearing on the same line (as it is
common for history formatting).
Instead of these long revision names and to avoid random-generated Alembic revisions it is suggested to user shorter names that are derived from a deterministic hash of the Registry version, including manager type, manager class name (without module) and manager version name.
6 Revision Forest¶
As we have multiple (almost) independent domains it makes sense to use independent revision history for each domain. Each domain will have separate revision tree with these properties:
- Root of the tree represents an empty schema, it is only used for identification and it is assigned a branch label with the name of the manager type (e.g. “datasets”). Its alembic revision name is derived from the same manager type name. Its corresponding migration script will be empty (except for metadata) an it is not is supposed to even run (we do not plan to use alembic to re-create schemas from scratch).
- Root will have one or more branches originating from it, one branch per manager class. Branches will be labeled after manager class name (e.g. “datasets-ByDimensionsDatasetRecordStorageManager”).
- Each revision on a branch corresponds to a version of the manager, its revision name is derived from the version number.
Here is an example of a revision tree for “datasets” manager which includes revisions for versions know today:
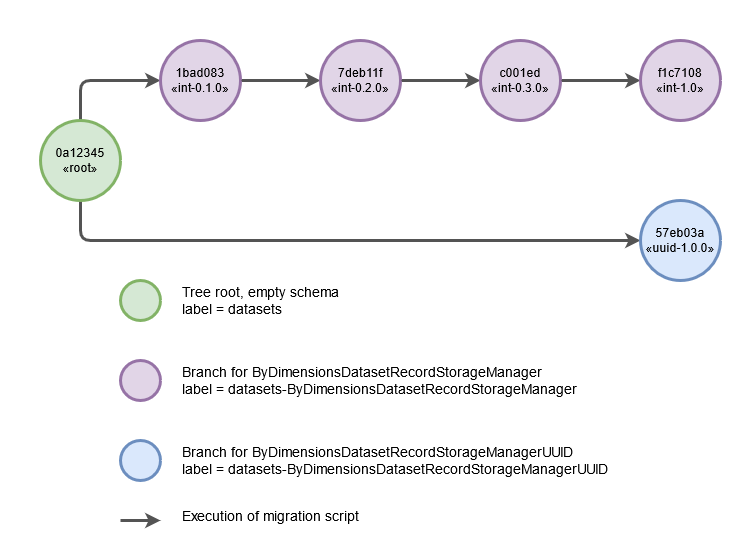
Note that in our case the branches are mutually exclusive, a database can only be on one branch at a time. Alembic branching model is more flexible, in general a database can contain multiple branches which can be merger at later time.
7 Branch Switching¶
Complications with the above model arise when there is a need to switch from one branch to another, e.g. “upgrade” datasets manager from ByDimensionsDatasetRecordStorageManager 1.0.0 to ByDimensionsDatasetRecordStorageManagerUUID 1.0.0. This is a simple “checkout” of a revision from a different branch but preserving and/or migration the data. The diagram for this may look like, with new migration arrow in red:
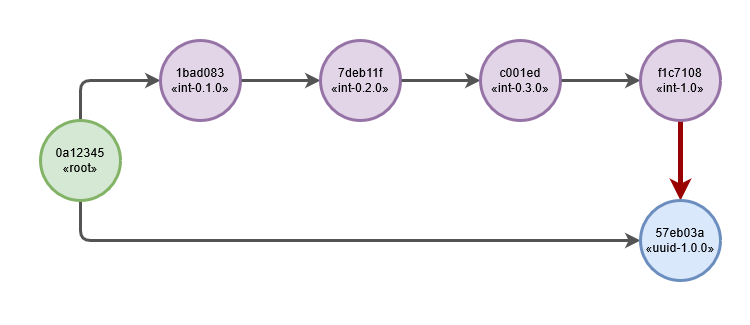
Unfortunately this sort of tree is not supported by alembic (branch merging is supported in general but not in a configuration like this). One possible workaround for this limitation is to generate separate branch which will have the same registry versions on it but different alembic revisions. This workaround is not very attractive as it will result in many more revisions and branches which is going to be a management issue.
Another workaround for this is to abuse alembic configuration flexibility and temporarily hide regular tree from alembic and replace it with a tree that enables the migration that was not allowed. To illustrate this approach this diagram shows this sort of “one-shot” revision tree with “hidden” parts of a tree grayed out:
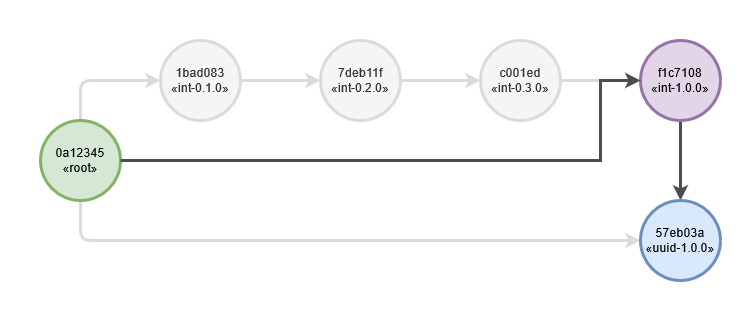
First migration on this tree (from root to «int-1.0.0») does not need to do anything as migration starting point will be «int-1.0.0» revision. Migration from «int-1.0.0» to «uuid-1.0.0» will have to do actual schema upgrade. After the one-shot schema upgrade the regular tree can be used again to continue migrations along linear branch history. Clearly this mechanism requires extreme care and these one-shot trees (there may be many of those) are normally hidden from alembic configuration. Special switch should be used to select exactly one one-shot tree.
This combination of regular trees with linear history and special one-shot trees should cover all necessary migration options.
8 Migration Directories¶
Hiding regular revision trees and replacing them with special one-shot trees
can be implemented by using multi-directory feature of alembic. In its
simplest setup alembic keeps all migration scripts in a single directory, but
it can also be configured to search more than one directory for the scripts.
This allows almost arbitrary sets of the scripts to be combined together to
form complete revision history. The limitation is that current revisions that
are specified in the database’s alembic_version table have to be found in
the resulting tree(s).
Because our migration history are spit into independent per-manager type trees it is natural to split the scripts between per-manager directories. One-shot trees will be stored in a special location, with a folder per-one-shot migration. Here is a possible directory hierarchy for such setup (migration scripts are named after their corresponding revision name):
├── _alembic // special folder for alembic use
│ ├── alembic.ini
│ ├── env.py
│ ├── script.py.mako
├── attributes // folder with scripts for 'attributes' manager
│ ├── f0a3531f97ca.py
│ ├── f22a777cf382.py
├── collections // folder with scripts for 'collections' manager
│ ├── 079a1bc77f25.py
│ ├── 1a93ca89bc27.py
│ ├── 3ce2d3adf1f5.py
├── datasets // folder with scripts for 'datasets' manager
│ ├── 059cc7b7ef13.py
│ ├── 2101fbf51ad3.py
│ ├── 38a9414ea7a2.py
│ ├── 576045cb7831.py
│ ├── 635083325f20.py
│ └── eb5a3cc76666.py
├── _oneshot // folder with scripts for one-shot migrations
│ └── datasets
│ └── int_1.0.0_to_uuid_1.0.0 // a specific one-shot migration
│ ├── 059cc7b7ef13.py
│ ├── 2101fbf51ad3.py
│ └── 635083325f20.py
For regular operations the configuration will include all per-manager
directories (attributes, collections, datasets in the tree above). When a
special one-shot migration needs to be performed the datasets folder will be
excluded for configuration and instead
_oneshot/datasets/int_1.0.0_to_uuid_1.0.0 will be used in its place.
9 Command Line Tool¶
Using alembic CLI for managing of this sort of setup is not very convenient,
one would need to modify its configuration filer frequently to reflect
location of the migration sets and database connection string. It would be
straightforward to implement our own set of commands that know how to
manipulate alembic configuration, extract database connection string from
butler configuration, and interpret contents of butler_attributes table.
Initial version of such interface was implemented in a separate package
daf_butler_migrate on top of the butler extensible CLI. Below is the
brief description of butler migrate sub-command and all its available
sub-commands. There are two major groups of commands, those that manage
migration history as a set of scripts and folders on local file system, and
those that work with the database performing checks or schema upgrades.
By default location of migration scripts is in
$DAF_BUTLER_MIGRATE/migrations folder, it can be changed with
--mig-path=PATH option.
9.1 Make revision tree¶
Usage:
butler migrate add-tree [--one-shot] TREE_NAME
Creates new revision tree, TREE_NAME is a manager type name (e.g.
“datasets”) for regular trees or a manager name and special migration name
(e.g. “datasets/int_1.0.0_to_uuid_1.0.0”) for one-shot migration trees.
9.2 List revision trees¶
Usage:
butler migrate show-trees [--one-shot] [-v|--verbose]
Prints a list of regular tree names, or special one-shot trees.
9.3 Make new revision¶
Usage:
butler migrate add-revision [--one-shot] TREE_NAME MANAGER_CLASS VERSION
Generates new migration script for migrating from most recent version of a
manager class defined in history to a new version. MANAGER_CLASS is a
manager class name with out module name.
9.4 Show revision history¶
Usage:
butler migrate show-history [--one-shot] [-v|--verbose] [TREE_NAME]
Print revision history, possibly limiting it to a single tree.
9.5 Stamp alembic_version table¶
Usage:
butler migrate stamp [--purge] REPO
Fills alembic_version table with the revision names derived from current
versions defined in butler_attributes table.
9.6 Display current database revisions¶
Usage:
butler migrate show-current [--butler] [-v|--verbose] REPO
Prints revisions defined currently in alembic_version table or in
butler_attributes table if --butler option is specified.
9.7 Upgrade database schema¶
Usage:
butler migrate upgrade [--one-shot-tree=TREE_NAME] [--sql] REPO REVISION
Upgrades database schema to a given revision using regular migration trees or
a special one-shot tree if --one-shot-tree is given.
9.8 Downgrade database schema¶
Usage:
butler migrate downgrade [--one-shot-tree=TREE_NAME] [--sql] REPO REVISION
Similar to migrate upgrade but works in opposite direction.